Retrieval evaluation, 07/12/22
Appunti della lezione in presenza del 7/12/22.
Se solitamente si parla di efficienza nell'ottenere dei risultati, nell'information retrieval bisogna principalmente valutare l'efficacia del programma, per cercare di capire se i risultati soddisfano le richieste. Questo si traduce nella misurazione della "felicità" dell'utente.
Web-engine: se l'utente trova quello che cerca, in un contesto general-purpose;
E-commerce: in un sistema di e-commerce, se il venditore riesce a vendere i propri prodotti;
Enterprise: principalmente si misura la velocità con cui si ottiene un documento;
In generale quindi la misura dipende dal contesto. Per misurare la rilevanza servono:
Una o più user information need, come ad esempio:
I'm looking for information on whether drinking red wine is more effective at reducing your risk of heart attacks than white wine.
Una suite di query di benchmark;
Dei documenti di benchmark;
Aver assegnato ad ogni documento una label "rilevante" o "non rilevante" rispetto ad ogni query;
R: set di documenti rilevanti a priori;
A: documenti ritornati;
RA: intersezione tra R e A
Due parametri:
Recall: \(\frac{|RA|}{|R|}\) \(\rightarrow\) quanti documenti rilevanti sono stati effettivamente restituiti;
Precision: \(\frac{|RA|}{|A|}\) \(\rightarrow\) tra i documenti ritornati, quanti documenti erano effettivamente rilevanti.
La precision e la recall sono tendenzialmente inversamente proporzionali;
Si consideri il seguente esempio:

recall \(\rightarrow\) quanti documenti rilevanti riesco a "richiamare";
precision \(\rightarrow\) quanto riesco a essere preciso sul mio output, senza sporcarlo con documenti non rilevanti;
Bisogna anche valutare l'ordinamento che viene fatto in base all'esigenza iniziale. Ricordiamo che più risultati vengono mostrati nel ranking, più aumenta la recall. L'idea per la valutazione dell'ordinamento è "fissare" 11 recall points dove viene misurata la precision. Per esempio, per avere un recall del 20%, 2 sui 10 documenti rilevanti devono essere presenti nel ranking. Per includerli, devono essere mostrati i primi 3 documenti.
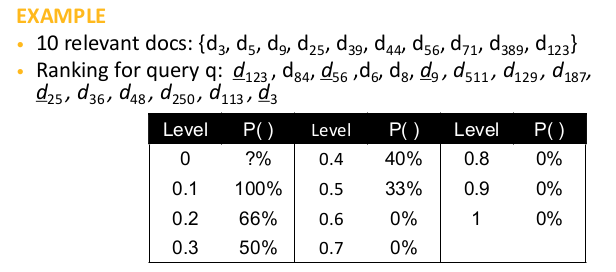
dato il numero limitato di recall points, si usa un metodo di interpolazione per determinare altri livelli di precisione:
\begin{equation} P(R_{j}) = max_{r_{j} \leq r \leq r_{j+1}}P(r) \end{equation}In questo modo si riescono a comparare query per cui il numero di documenti rilevanti a priori è diverso. Infatti basta definire dei punti di recall standard (10%, 20%, ...100%) i quali potrebbero anche non essere utili per una determinata query (si pensi ad una query per cui si sono definiti 3 documenti rilevanti: senza un metodo di approssimazione non si riuscirebbe a definire una precision per un recall point come 50%, che rappresenterebbero un set di risultati contenente 1 documento rilevante e mezzo.)
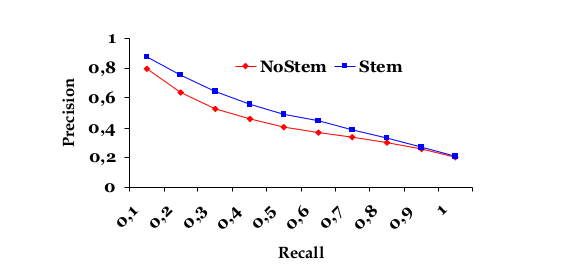
Se si plottasse la tabella sopra, si riuscirebbe a vedere l'andamento della precisione all'aumentare della percentuale di documenti rilevanti che vogliamo che siano ritornati. Ovviamente l'ideale sarebbe mantenere questa curva il più in alto possibile.
Precisione media su più query, per ogni livello di recall. Tengo fermo un livello di recall, scorro le query (facendo la media delle precision).
Ovviamente la cosa giusta da fare è calcolare l'average precision a ogni livello di recall per un'insieme di query.
\begin{equation} \bar{P}(r) = \sum_{i=1}^{N_{q}}{\frac{P_{i}(r)}{N_{q}}} \end{equation}Quindi per ogni recall level si ottiene una average precision. Per capire quindi come il sistema performa in generale, si fa un plotting average precision / recall.
Ovviamente si cerca di ottenere una curva più "alta" possibile.
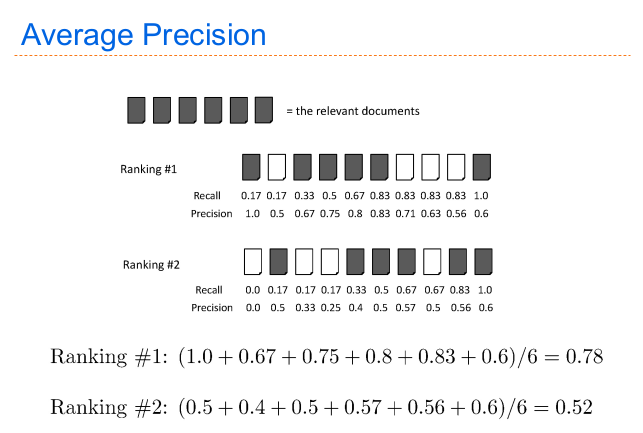
I vantaggi principali di questo metodo sono la sua semplicità e la visione d'insieme che viene data sulla "performance" del sistema. E' utile avere una singola curva come metro di valutazione.
Tengo ferma una query, scorro i livelli di recall (facendo la media). I valori di recall più sensati da avere sono \(i/|Rq|\), dove \(i\) scorre sul numero di documenti rilevanti per quella determinata query.
Un'altro metodo di valutare un sistema è quello di limitarsi all'analisi delle query separatamente, in modo da limitare l'impatto di valori fuori curva. Il procedimento da seguire è il seguente:
Si fissa una query \(q\);
Per ogni livello di recall, si applica la query ottenendo un valore di precision (interpolato, dato che si usano gli standard recall levels );
Si fa la media di tutti i valori ottenuti;
Dove IAP sta per Interpolated Average Precision. Altrimenti se non si vogliono usare gli standard recall levels per ottenere una misura più "ad hoc" per la query, si usa questa formula:
\begin{equation} NIAP = \sum_{r = 0}^{n}{\frac{P_{q}(r/R_{q})}{|R_{q}|}} \end{equation}Dove NIAP sta per Non-Interpolated Average Precision. Queste misure favoriscono sistemi che restituiscono documenti rilevanti "velocemente".
Semplicemente si calcola la media per le varie Single Precision Value ottenuti dalle varie query. E' quindi una media delle medie. E' sicuramente una delle misure più utilizzate
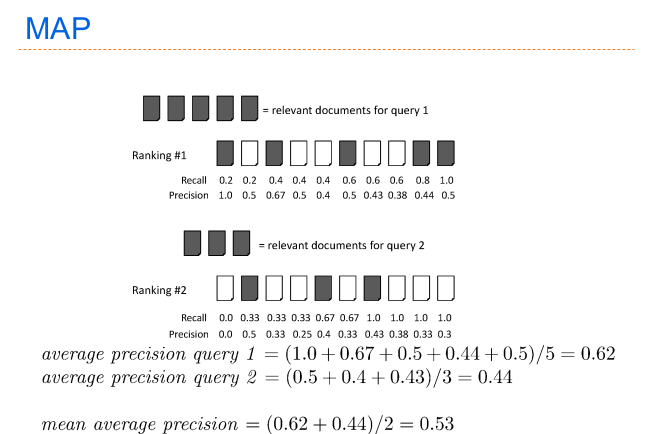
Alcune feature da tenere in mente:
Ogni query conta allo stesso modo nel calcolo finale;
Se si usa questo metodo di valutazione, si suppone che l'utente voglia trovare molti documenti nelle prime \(n\) posizioni (circa). Non è detto che sia adatto per tutti i contesti.
Calcolo quanti documenti rilevanti ho restituito rispetto al caso ideale in cui nei primi \(n\) documenti ho restituito tutti ed \(n\) i documenti rilevanti.
Anche qua in un secondo momento si possono scorrere tutte le query di benchmark e valutare diversi sistemi in base ai risultati ottenuti, sotto è riportata la forumula.
Si basa su una singola query e restituisce un singolo valore. E' un metodo molto semplice dato che non usa la recall. Semplicemente:
Si applica la query, ottenendo un ranking dei documenti;
Si supponga che il pool di documenti rilevanti a priori per quella query contenga \(n\) documenti;
Si divide il numero di documenti rilevanti nei primi \(n\) ( all'interno del ranking) per \(n\).
Per vedere a occhio quale sistema funziona meglio con la query \(i\):
\begin{equation} RP_{A/B}(i) = RP_{A}(i) - RP_{B}(i) \end{equation}
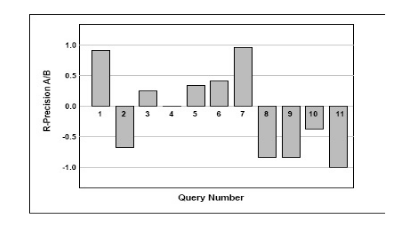
Possibile assenza di benchmark, ma anche la sua costruzione costituisce un problema a parte ( i documenti vanno anche supervisionati dal programmatore/o da un responsabile)
Recall e Precision sono soltanto una piccola parte di tutto ciò che concerne un sistema di information retrieval, andrebbero considerati molti più parametri.
Per alcuni sistemi il meccanismo più indicato non è l'ordinamento totale, ma un'ordinamento parziale dei risultati: in questo caso precision e recall risultano non adeguate. Questo può capitare se si sta facendo un ranking considerando molti parametri, e il sistema non sa quale parametro ha "più peso" rispetto agli altri. Esempio: booking chiede all'utente "rispetto a cosa" effettuare l'ordinamento dei risultati (prezzo, vicinanza al centro, presenza/assenza wifi, recensioni, ecc...).
Infatti recall e precision si basano sul sapere la "rilevanza" di un oggetto. In casi complessi, non posso avere direttamente questa informazione, devo chiedermi "rilevante rispetto a cosa?" \(\rightarrow\) più parametri potrebbero influire sulla rilevanza!
La media armonica ha un valore alto se entrambi i valori hanno un valore alto. Deve esserci "armonia" tra i due valori.
Misura che dato un risultato di una query, combina direttamente precision e recall per ottenere un'unico valore.
\begin{equation} \frac{2*prec*call}{prec+recall} \end{equation}se b == 1 allora è il complementare della media armonica;
se b>1 si infatizza la precision;
se b<1 si infatizza la recall;
Dato un pool iniziale di documenti, l'utente assegna ad ognuno un certo punteggio discreto ( da 0 a 3) in base all'"utilità" del documento rispetto ad una determinata query. Dopo aver fatto ciò, la query viene applicata e viene ritornato un ranking. L'idea del DCG è quella di dare più peso ai documenti che appaiono più in alto nel raking:
\begin{equation} DCG_{p} = rel_{1} + \sum^{p}_{i=2}{\frac{rel_{i}}{\log_{2}{i}}} \end{equation}N.B: il primo elemento viene escluso dalla sommatoria dato che verrebbe diviso per 0.
Gli evidenti problemi di questo tipo di valutazione sono l'inefficienza e tal volta inefficacia dei giudizi umani, che richiedono anche molto tempo.
Con la formula standard riportata sopra, per i == 2 il denominatore all'interno della sommatoria vale 1, perciò il secondo elemento nel ranking ha la stessa rilevanza del primo. Questa può essere vista come una "feature" o come un "bug", dipende dal contesto.
Nella versione normalizzata della formula, il punteggio di DCG di ogni query viene diviso per il punteggio "ideale", ossia quello in cui i valori di DCG sono in ordine decrescente nel ranking.
I risultati del ranking vengono solitamente "estesi" con dei metadati aggiuntivi, per dare all'utente un'idea iniziale del documento a prima vista. Esistono 2 metodi per effettuare questa operazione:
Static summary (query indipendent): i "metadati" di ogni documento sono sempre gli stessi, indipendentemente dalla query. Lo static summary di un documento potrebbe essere:
le prime 50 parole del contenuto;
una serie di keywords calcolate in vari modi;
un riassunto generato da algoritmi di machine learning;
Dynamic summary (query dipendent): le informazioni aggiuntive mostrate dipendono dalla query, vengono calcolate in modo dinamico. Si cerca di far capire all'utente per quale motivo quel particolare documento è rilevante per la sua query. L'idea è che questi snippet devono essere concisi, semplici, e rilevanti per poter rispondere in poche parole alla query dell'utente. Si preferiscono snippet che contengono i termini della query in una frase concisa.