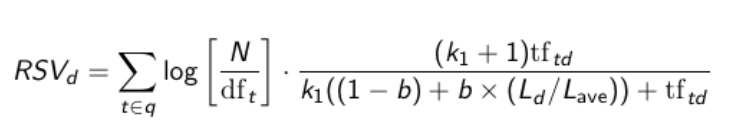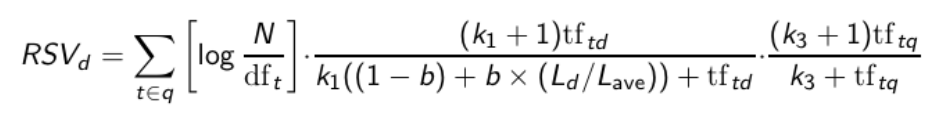Modelli Fuzzy e OkariBM25, 17-11-22
Breve introduzione ai modelli di ranking Fuzzy e OkariBM25.
Il modello Fuzzy si basa sulla Fuzzy set theory
La Fuzzy Set Theory è una teoria insiemistica in grado di gestire problemi legati a classificazioni imprecise o ambigue.
In generale, si cerca di rilassare il modello booleano classico in modo da considerare anche un certo valore di incertezza sul significato del testo.
Definizione di Insieme Fuzzy \(\Downarrow\)
Insieme i cui elementi hanno un certo grado di appartenenza, anche detto Valore di Membership.
Input: (i) query booleana, (ii) contesto reale;
Output: valore di membership dell'intero documento rispetto alla query;
Nonostante questo tipo di approccio "non crisp", quindi in cui gli insiemi non hanno "confini" ben delineati, si possono comunque usare gli operatori booleani per effettuare operazioni insiemistiche. Alcune definizioni:
\(\mu_{A}(x) \rightarrow\) Valore di membership dell'elemento \(x\) rispetto all'insieme \(A\).
In ambito di information retrieval, si potrebbe pensare al valore di membership come la similarità tra l'elemento \(d_{j}\) (documento) e l'insieme \(q\) (query).
\begin{equation} \mu_{q}(d_{j}) = sim(q, _{j}) \end{equation}dove \(sim(q, _{j})\) indica la similarità calcolata tramite il modello vettoriale.
La query Q viene scomposta nei vari termini \(A_{i}\), a cui viene associato un fuzzy set \(D_{A_{i}}\)
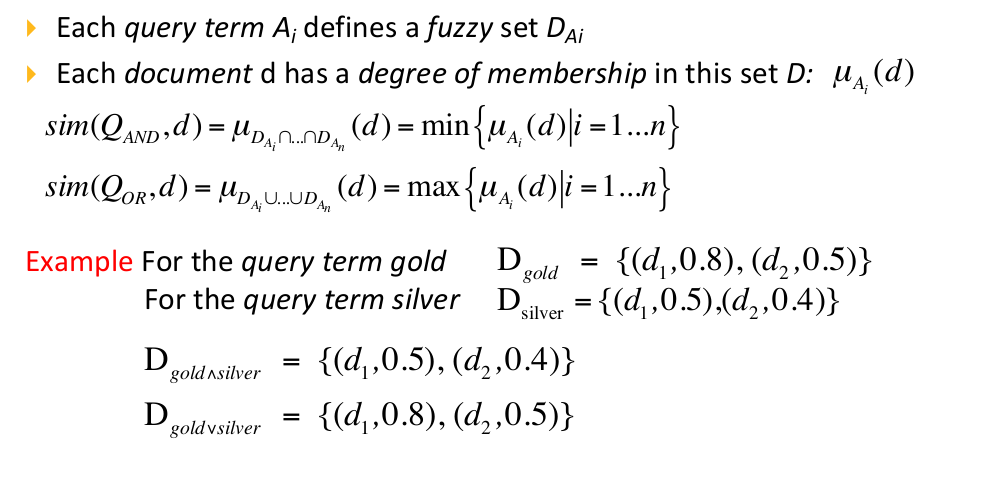
La parte di query "gold" ha similarità pari a 0.8 con il documento 1, e di 0.5 con il documento 2.
La parte di query "silver" ha similarità pari a 0.5 con il documento 1, e di 0.4 con il documento 2.
Ora ci si interroga sul valore di Membership dei documenti 1 e 2 alle query: \(gold \cap silver\) e \(gold \cup silver\).
Si usa la formula e si seleziona il minimo nella query \(\cap\) (intersezione) il massimo nella query \(\cap\) (unione);
Questo modello è un miglioramento del BIM, in quanto tiene conto di questi ulteriori parametri:
(IMP) term frequency (frequenza dei termini nei documenti);
(+) lunghezza dei documenti;
(+) In certi casi, anche della frequenza dei termini nelle query;
Nella prima formula di partenza, per il ranking di un documento D si considera semplicemente la sommatoria della \(idf\) (indice di rarità di un termine all'interno di un corpus di documenti) dei termini presenti sia nella query che nel documento selezionato: