Livello 4, Trasporto
Appunti della lezione in presenza 15/11/22. Si è parlato ampiamente del livello 4, seguendo abbastanza fedelmente le slide.
I due protocolli più diffusi e usati a livello 4 sono il TCP(Transfer Control Protocol) e l'UDP(User Datagram Protocol). Questi regolamentano la comunicazione tra processi applicativi su host diversi o addirittura sulla stessa macchina. Le due caratteristiche fondamentali di questi protocolli sono:
Multiplexing e demultiplexing di messaggi tra processi.
Rilevamento degli errori
UDP implementa principalmente queste due funzionalità, mentre TCP ne aggiunge molte altre, come:
Garanzia dell'affidabilità del trasferimento.
Gestione di congestioni di rete.
\(\Rightarrow\) TCP risulta quindi essere molto complesso rispetto a UDP.
Multiplazione \(\rightarrow\) invio dei pacchetti
Demultiplazione \(\rightarrow\) ricezione dei pacchetti: dallo stesso livello 3 si deve capire a quale processo il pacchetto deve essere inoltrato.
Questi protocolli di comunicazione implementano una logica basata sulle porte. Mettiamo che il processo P1 debba inviare un pacchetto a P3: entrambi i processi saranno identificati da una porta sorgente e una porta destinataria.
server \(\rightarrow\) connessione passiva;
client \(\rightarrow\) connessione attiva;
Un processo(server) deve "aprire" una porta sul suo sistema operativo, e aspettare delle richeste su quella porta da parte di un client. Un processo quindi "prenota" una porta, ciò significa che:
più processi non possono prenotare la stessa porta
quando un server prenota una porta deve specificare che protocollo ha intenzione di usare.
Ricordiamo che nel datagram IP, nel campo "protocol", c'è l'informazione sul livello 4: il sistema operativo riesce già a capire quale protocollo deve gestire il pacchetto soltanto leggendo l'header IP.
Il client quando si connette ad una porta, specifica anche una porta sorgente per gestire eventuali risposte da parte del server. Spesso la porta sorgente del client viene scelta in modo autonomo dal sistema operativo.
Numero intero da 0 a \(2^{16}-1\), quindi l'informazione occupa 16 bit.
[0,1024] \(\rightarrow\) Well Known Ports, sono state associate in modo ben definito a dei protocolli applicativi "standard". Esempio: se un server ascolta sulla porta 80, allora DOVREBBE implementare il protocollo applicativo http.
Telnet \(\rightarrow\) 23
SMTP \(\rightarrow\) 25
...
In questo modo, in certi casi si riesce ad omettere l'informazione riguardo alla porta, che viene recuperata dallo standard.
Queste well known ports, oltre ad essere parte dello standard, sono gestite diversamente dal sistema operativo. Ad esempio, per mettere un processo arbitrario in ascolto su una w.k.p, servono privilegi di amministratore;
[1024-49151] \(\rightarrow\) Registered ports.
altre porte \(\rightarrow\) porte completamente scorrelate rispetto a qualsiasi protocollo applicativo noto.
Su linux esiste un file che istruisce il SO sul mapping numero di porta / processo applicativo, per leggerlo si usa il seguente comando:
less /etc/services
Esiste quindi una quintupla che identifica un generico flusso a livello trasporto su internet:

Si da un'ulteriore definizione che può tornare utile quando si studia il livello 4:
packet flow \(\rightarrow\) flusso di pacchetti appartenenti alla stessa comunicazione. Per identificarlo, non basta conoscere soltanto la sorgente e la destinazione. Infatti ad esempio nel payload dei pacchetti ICMP c'è memorizzato un ID che identifica appunto il flusso di pacchetti.
Si parte quindi dallo studio del protocollo più semplice: l'UDP. Esso fornisce due servizi:
Multiplexing e Demultiplexing.
Controllo dell'errore.
A differenza del protocollo TCP, il protocollo UDP non garantisce l'affidabilità della consegna dei pacchetti.
Ma cosa significa UDP?
User DATAGRAM protocol \(\rightarrow\) l'applicazione che usa il protocollo sa che deve inviare dei pacchetti, quindi sa che deve adottare un approccio prettamente orientato al packet switching. Questi hanno una dimensione massima, pari a
ricordiamo che a sua volta il pacchetto IP sarebbe limitato dalla grandezza dei pacchetti del livello H2N, ma IP in realtà è in grado di frammentare i pacchetti, quindi "realmente" il problema non sussiste. Il problema ci sarebbe se non ci fosse la possibilità appunto di frammentare i pacchetti.

Il campo lunghezza contiene la lunghezza totale del pacchetto (header + dati).
Il campo checksum contiene anche informazioni inerenti al livello 3, perchè si vuole fare una sorta di controllo anche su quel livello, dato che le informazioni ivi contenute hanno un'impatto sulla logica applicativa del livello 4.
Ma nell'header del protocollo IPv4 c'è già il checksum... infatti può sembrare ridondante inserire un'ulteriore controllo a livello 4. \(\rightarrow\) nel protocollo IPv6 infatti il checksum non viene inserito per risparmiare spazio.
L'algoritmo di checksum prende in input 3 elementi:
pseudoheader (alcune informazioni prelevate dall'header di livello 3)
header UDP
payload UDP
Ecco lo pseudoheader nello specifico \(\Downarrow\)
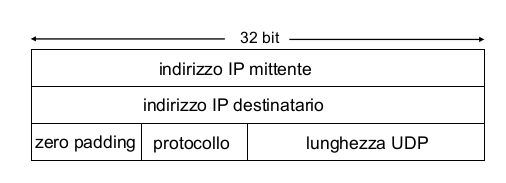
Il checksum viene poi inserito nel pacchetto che verrà inviato: il destinatario si calcolerà il checksum con lo stesso algoritmo e verrà fatto un matching per capire se ci sono stati errori. In particolare:
Il mittente calcola il checksum facendo il complemento a 1 della somma di tutti i campi dello pseudo header e del pacchetto UDP;
Il mittente inserisce questo campo all'interno dell'header UDP e lo invia al destinatario.
Il destinatario calcola il suo checksum allo stesso modo, basandosi su pseudo-header e pacchetto UDP ricevuto;
Il destinatario fa la somma tra il suo checksum e quello che gli è arrivato: se questa genera una stringa di tutti 1, allora la trasmissione è avvenuta correttamente, altrimenti ci sono stati errori.
A livello 4 alla fine interessa sapere se il mittente e il destinatario sono quelli corretti, a meno di dettagli secondari.
Ecco (in breve) le principali caratteristiche aggiuntive del protocollo TCP:
Garanzia di affidabilità
Il paradigma è:
Orientato alla connessione: quando si vuole comunicare si esegue un sottoprotocollo per stipulare una connessione col destinatario.
Orientato allo scambio di un flusso di dati: scambio di una quantità illimitata di byte.
Il sistema operativo fa credere all'applicazione che tutti i dati vengono trasmessi in modo affidabile.
Capacità di rilevazione dell'errore;
Capacità di reazione all'errore;
Quando si parla di rilevazione di un'errore, si fa riferimento ai seguenti problemi:
compromissione dell'integrità del pacchetto, rilevata tramite il checksum;
pacchetto che non arriva;
pacchetto che arriva più volte;
consegne in ordine sbagliato;
Esistono dei protocolli applicativi a cui non interessano tutte le funzionalità di TCP, ma soltanto alcune. Solitamente questi protocolli usano una versione modificata di UDP, per risparmiare sulla logica! (Ad esempio, su una lunga trasmissione di streaming video, l'arrivo di tutti i pacchetti può anche non essere di fondamentale importanza.)
Il mittente deve quindi avere dei feedback da parte del destinatario, in modo da capire se la comunicazione è andata a buon fine o se ci sono stati dei problemi.
\(\Rightarrow\) logica di acknowledgment (o feedback):
acknowledgment positivo: informazione che il destinatario invia ogni volta che riceve una trasmissione corretta.
acknowledgment negativo: il destinatario segnala un errore nella comunicazione.
Nella maggior parte dei casi viene usato soltanto l'ack(nowledgment) positivo, per segnalare la ricezione corretta del pacchetto. Il destinatario invece sta in silenzio se rileva degli errori, facendo scattare un "timeout".
Se il mittente invia un'informazione e non riceve un ack, allora si assume che la comunicazione non sia avvenuta correttamente.
TCP è stato sviluppato considerando che la maggior parte degli errori è dovuto a dei pacchetti non consegnati, per il sovraccarico di router. Per questo si fa uso solo di un timeout.
Il problema di pacchetti distorti è raro. Tutta questa logica è gestita dal SO.
In generale, il concetto è quello che i dati devono essere ritrasmessi, non c'è molto altro da dire.
Instaurare una connessione permette ad esempio di capire se il processo destinatario esiste o meno! E' quindi utile avere una fase di apertura per testare la capacità di comunicare del destinatario. In totale le fasi (tutte affidabili) sono:
Apertura
Utilizzo
Chiusura
Quando si usa TCP il singolo pacchetto prende il nome di segmento. Questo perchè TCP separa un flusso dati in molti segmenti.
La logica con cui TCP separa i dati si basa sul fatto che la dimensione massima di ogni segmento deve essere minore dell'MTU dell'interfaccia, in modo che il protocollo IP non debba splittare ulteriormente i pacchetti.
sequence number, viene usato dal destinatario per identificare segmenti duplicati, e per capire l'ordine dei segmenti TCP.
Il mittente e il destinatario hanno un buffer per gestire l'ordine di invio durante la comunicazione. E' una sorta di "sala d'attesa" in cui i dati vengono riordinati per garantire maggiore affidabilità.
Ecco altri concetti importanti:
La connessione virtuale che si crea tra i processi è full duplex: una volta che la connessione è creata, non ci sono più differenze tra client e server: si possono inviare dati a vicenda.
controllo di flusso \(\rightarrow\) tcp regola il tasso di trasmissione di dati in base alla capacità di ricezione del destinatario, in modo da cercare di impedire la congestione della rete.
TCP è un Protocollo asincrono: il SO potrebbe aspettare ad inviare dati, appunto per la questione dell'affidabilità e della sicurrezza. A volte il processo applicativo destinatario può aspettare a richiedere i paccheti.
Il processo destinatario che riceve dei dati dal sistema operativo è sicuro che essi siano ordinati. Quindi si ha una logica trasparente, il protocollo TCP si occupa di riordinarli e assicurarsi che i dati ricevuti sono uguali ai dati inviati.
comunicazione in tempo reale
disponibilità di banda tra mittente e destinatario
Comunicazioni multicast (un mittente e molti destinatari)
Etereogenità degli host e dei processi: da ogni lato deve essere implementata della logica per attivare e concludere le comunicazioni;
Timeout : deve essere lo stesso per due processi locali rispetto a un timeout tra due processi agli estremi del mondo? \(\rightarrow\) c'è bisogno di usare un timeout adattivo;
Possibili ritardi nella consegna, vista la complessa logica implementata;
Gestione di host con caratteristiche computazioniali eterogenee;
Gestione dell'eterogeneità delle connessioni di rete, che possono essere molto diverse.