Segmento TCP, Trasporto, p2(t)
Definiamo alcune proprietà importanti:
Tempo di propagazione: quanto tempo ci mette l'informazione a raggiungere il destinatario. E' un dato derivato, pari a \(RTT/2\)
Utilizzazione: più è alto, meglio è! E' un valore percentuale che indica la percentuale di utilizzo di una risorsa in un periodo di tempo.
Rate: capacità trasmissiva della rete;
L(pacchetto): lunghezza del pacchetto che si trasmette. Il pacchetto è l'unità trasmissiva minima.
La figura sotto dovrebbe chiarire la differenza tra tempo di trasmissione e tempo di trasferimento:

Tempo di trasmissione:
Tempo di trasferimento
E' essenzialmente il tempo di propagazione + tempo di trasmissione + propagazione dell'ack (vista mittente).
\begin{equation} [RTT_{pkt}/2 + L(pkt)/Rate] + [RTT_{ack}/2] \end{equation}

Per migliorare le prestazioni e ridurre i "tempi morti", si usano tecniche di pipelining, in modo da sfruttare al meglio le risorse di rete.
Se invece di mandare un pacchetto solo se ne mandassero altri 2 "durante l'attesa", il numero totale di pacchetti inviati diventa 3 e il valore di Utilizzazione triplica.
Per implementare il pipelining servono dei buffer di memorizzazione da entrambi i lati della comunicazione. Ad esempio, finchè il client non ha ricevuto le conferme dal server rispetto ai pacchetti inviati,deve mantenere questi ultimi in memoria (una zona dedicata del buffer). Dall'altro lato il destinatario deve effettuare un'operazione simile: nel caso in cui soltanto il secondo e il terzo pacchetto vengono ricevuti di un flusso costituito da 3 pacchetti, finchè non arriva anche il primo gli ultimi due devono essere mantenuti in memoria!
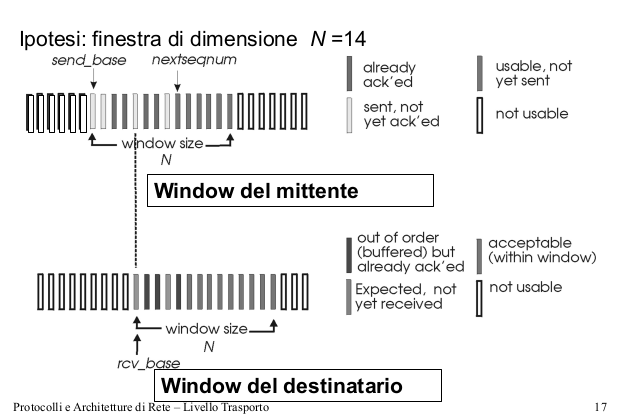
La gestione dei buffer prima descritta prende anche il nome di sliding window. Ad ogni istante ciascun mittente gestisce una finestra scorrevole sugli indici numerati dei segmenti, e solo quelli all'interno della finestra possono essere trasmessi.
La dimensione massima della finestra del mittente è controllata dal destinatario, tramite delle informazioni contenute negli ack;
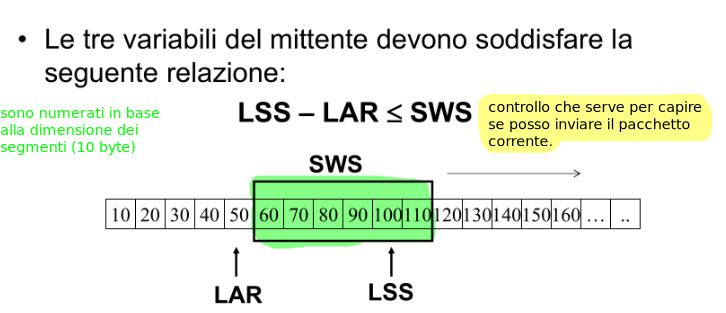
Alcuni parametri:
SWS (Sender Window Size)
LAR (Last Ack Received)
LSS (Last Segment Sent)

RWS (Receive Window Size)
LAS (Largest Acceptable Segment)
LSR (Last Segment Received)
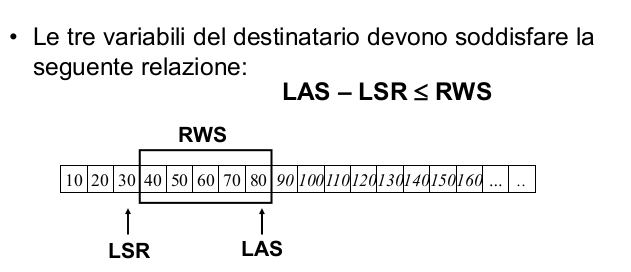
L'utilizzo di una finestra di scorrimento anche da parte del destinatario serve a gestire l'arrivo di pacchetti out of order. Infatti l'LSR indica l'ultimo pacchetto ricevuto senza alcun "buco mancante" prima. Se le finestre del destinatario e del mittente non fossero in qualche modo sincronizzate, il destinatario potrebbe ricevere segmenti troppo sparsi e avere difficoltà nella gestione!
Quando arriva un segmento \(N\):
Se \(N\) \(<\) LSR \(\rightarrow\) pacchetto duplicato;
Se \(N\) \(>\) LAS \(\rightarrow\) pacchetto out of window, da scartare;
Se LSR \(<\) \(N\) \(<=\) LAS \(\rightarrow\) tutto ok, pacchetto inserito nel buffer;
Con questi algoritmi si intende gestire il mancato arrivo di un pacchetto ack, quindi dopo la scadenza del timeout;
Questo algoritmo agisce su un tipo di comunicazione in cui il destinatario NON gestisce una finestra di scorrimento, ma fa uso soltanto di un buffer di ricezione.
Nel caso in cui avvenga un timeout per il paccheto \(i\), allora vengono ritrasmessi tutti i segmenti con \(N\) >= \(i\);
Il destinatario manda degli ack cumulativi:
ACK(\(n\)) = sono arrivati correttamente i primi \(n\) segmenti;
In questo caso anche il destinatario gestisce una sliding window.
Gestisce un time-out per ciascun pacchetto, e ritrasmette soltanto i segmenti per i quali non ha ricevuto ACK.
Invia ACK relativo a ciascun segmento ricevuto correttamente.
Vantaggio: il destinatario riesce a gestire "agilmente" pacchetti out-of-order grazie alla sliding window.
Svantaggio: la rete viene riempita di pacchetti ack: non essendo cumulativi, devono essere inviati e recapitati tutti gli ack corrispondenti ai pacchetti ricevuti. Nell'approccio precedente (con ack cumulativo), se ack1 e ack2 vengono persi ma ack3 arriva correttamente, allora l'arrivo di ack1 e ack2 non è più necessario!

Nell'effettiva implementazione del protocollo TCP, viene usato un'approccio ibrido fra i due, il cui funzionamento è circa il seguente:
se il destinatario riceve un pacchetto fuori sequenza, non manda un ack confermando quella ricezione, ma manda un ack comunicando qual'è il prossimo segmento che si aspetta.
Esempio:
Destinatario: arrivano i segmenti 2 e 3 \(\rightarrow\) comunica che gli manca l'1;
Mittente: prova a re-inviare l'1, che magari è andato perso;
Destinatario: gli arriva il pacchetto 1, comunica che ora vuole il 4;
Mittente: fa avanzare la sliding window posizionando l'inizio sul 4;
Il protocollo TCP gestisce il resizing della sliding Window, in base alle condizioni della rete e degli host coinvolti (principio di adattività)! Eseguendo (i) controllo di flusso e (ii) controllo di congestione, TCP adattadinamicamente le dimensioni delle sliding window!

TCP deve assicurarsi di non inviare più segmenti di quanti il destinatario può riceverne. Il controllo di flusso permette di ridimensionare la finestra di scorrimento in base a informazioni ricevute esplicitamente dal destinatario. Essenzialmente il destinatario informa esplicitamente il mittente rispetto alla quantità di spazio libero nel suo buffer di ricezione. Questa è un'informazione aggiuntiva che viene "appesa" al segnale di ACK. Se il destinatario ha esaurito il buffer, la trasmissione si sospende e riprende quando il destinatario sarà di nuovo in grado di ricevere dei byte.
Ma come fa il mittente a sapere quando il destinatario è in grado di ricevere byte?
\(\rightarrow\) ogni tanto il mittente manda dei pacchetti molto piccoli (1 byte) in modo da poter ricevere una risposta ACK dal destinatario, che comunica la sua disponibilità nel buffer; Alcuni termini tecnici:
Advertised Window: dimensione della finestra massima di ricezione comunicata dal destinatario;
Flow Window: dimensione calcolata dal mittente in base all'informazione ricevuta;
TCP deve assicurarsi di non inviare più segmenti di quanti la rete è in grado di gestire; Gli effetti di una rete congestionata sono principalmente:
perdita di pacchetti (overflow dei buffer nei router);
lunghi ritardi (tempi di attesa nei buffer dei router);
Nel TCP il controllo di congestione avviene a livello end-to-end, analizzando le perdite di pacchetti ed i ritardi nei nodi terminali.
Il controllo di congestione si basa su 2 principi:
Slow start: inizio graduale dell'aumento della congestion window;
Additive Increase-Multiplicative Decrease: vengono messi sempre più pacchetti in pipe seguendo un'andamento lineare, finchè non si verifica una di queste 3 casistiche:
Si raggiunge un limite fisico dato dall'interfaccia di rete;
Si raggiunge la dimensione della flow window;
Si rilevano delle perdite di pacchetti o dei ritardi;
Se quindi si verificano problemi si applica una decrease moltiplicativa di un fattore 2 rispetto ai pacchetti messi in pipe.
Throughput (tasso di trasmissione):
w \(\rightarrow\) numero di segmenti nella finestra, quindi è praticamente la "largezza" della finestra. L'obbiettivo del controllo di congestione è quello di massimizzare questo parametro senza creare problemi;
MSS \(\rightarrow\) dimensione massima del segmento;
Riassumento, l'algortimo di controllo di congestione si basa su queste due fasi:
Slow start: all'inizio la finestra di congestione è molto piccola (1 o 2 MSS). Per ogni ack ricevuto, si aumenta la dimensione in modo lineare o esponenziale; Se si raggiunge una treshold si va in fase di congestion avoidance:
Congestion avoidance:
se la rete è in uno stato di non congestione, allora la dimensione della CW è incrementata di 1 MSS per ogni ack;
se invece si rileva una congestione (pacchetti duplicati, timeout) c'è un ritorno alla fase di slow-start;
Vediamo ora due algoritmi diversi che implementano il concetto di congestion avoidance \(\Downarrow\)
Quando si rilevano delle perdite la CW torna a 1. Si vede bene dal grafico l'andamento a dente di sega.
# slow start terminato, CW > treshold if not(perdita): for each ack received: CW++ else: treshold = CW/2 CW = 1 goto slow-start

In questo caso in base al tipo di perdita/errore rilevato l'algoritmo assume un comportamento diverso:
Timeout \(\rightarrow\) la window viene ridotta a 1;
Ack duplicato \(\rightarrow\) la window viene dimezzata; viene quindi applicata una regola "più leggera" perchè comunque la rete è in uno stato pseudo-funzionante: un pacchetto è stato perso (altrimenti non ci sarebbero ack duplicati) ma almeno altri 3 segmenti sono stati ricevuti dal destinatario (nel caso in cui gli ack duplicati siano 3)
while(no loss): for each ack received: cw++ treshold = cw/2 if(loss detected by timeout): cw = 1 goto slow-start if(loss detected by triple duplicate ACK): cw = cw/2 # fast recovery, si torna a treshold

Algoritmo pro-attivo, effettua dei controlli preventivi per ridimensionare la CW. Si basa sul presupposto che l'aumento della latenza è graduale. L'idea è quella di diminuire linearmente la dimensione della CW quando si osserva un'aumento dell'RTT. A differenza del Reno, questo algoritmo individua perdite di pacchetti analizzando l'RTT e non gli ACK replicati.
Fairness : "correttezza" degli algoritmi nello spartirsi la banda disponibile.
In presenza di flussi dello stesso tipo sia il Reno che il Vegas sono considerati "fair". Se invece si considera una situazione in cui entrambi gli algoritmi lavorano assieme, allora è verificato sperimentalmente che il Reno si appropria della maggior parte della banda disponibile.
Ora che si ha una visione più completa dell'argomento, si può fare un recap sul confronto tra i due protocolli:
👉🏿 Perchè usare UDP anzichè TCP?
UDP non introduce un ritardo per iniziare una connessione;
Un generico server supporta più connessioni se usa UDP, che non deve mantenere la connessione end-to-end;
I segmenti sono più piccoli in UDP, quindi si trasmettono meno dati \(\rightarrow\) maggiore velocità di propagazione dei segnali. \(\rightarrow\) UDP è quindi più utile per connessioni real-time;
Non tutte le applicazioni richiedono la consegna in ordine dei pacchetti;